
“无法写入核心转储”
Joakim Nordström 于 2021 年 4 月 30 日发表

照片由 David Libeert 拍摄
当 Java 虚拟机 (JVM) 崩溃时(请参阅此处),我检查了 HotSpot 错误文件 hs_err。一个常见的“错误”是“无法写入核心转储”。
“无法写入核心转储。”
但是,无法写入核心转储并非导致 JVM 崩溃的错误,它只是 JVM 通知您未写入核心转储。
TL;DR 如果您只想摆脱无法写入核心转储的错误,您可以直接跳转到要使用的参数。
请注意这不会解决崩溃问题,您只会得到一个占满系统的大文件,即核心转储。
核心转储或 Windows 上的“迷你转储”是崩溃进程的快照。如果您想要一个类比,您可以想象 JVM 是一辆四处行驶的汽车,然后突然撞到了什么东西,比如另一辆汽车、砖墙或行为不端的驾驶员。为了给保险公司提供一些东西以便查看并尝试找出发生了什么,JVM 可以拍摄崩溃现场的照片。
不同的操作系统创建核心转储的方式不同。Windows 在 dbghelp.dll DLL 中具有 MiniDumpWriteDump 函数,它由 JVM 调用以触发核心转储。在 POSIX 操作系统系列(即 Unix、Linux 和 macOS)上,abort() 函数 调用将使操作系统生成核心转储。
用于启用核心转储写入的 JVM 参数 -XX:+CreateCoredumpOnCrash 在 JDK 9 及更高版本上默认启用。如果您仍在使用 JDK 8,则该参数的名称改为 -XX:+CreateMinidumpOnCrash,这仅在 Windows 上有意义——在其他操作系统上,该参数会被简单忽略。
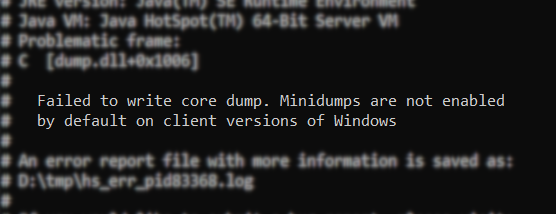
无法写入核心转储。默认情况下,Windows 的客户端版本未启用迷你转储
“默认情况下,Windows 的客户端版本未启用迷你转储”消息中的“客户端”是指在Windows 客户端上运行,而不是Windows 服务器;不要与旧的HotSpot 客户端/服务器 VM 区别混淆。在 Windows 客户端上,您必须告诉 JVM 写入迷你转储。这与 Windows 本身无关,因此您无需更改 Windows 中的任何设置(有人建议启用 Windows 崩溃时的设置,但这不适用于此处)。检查我们是否在 Windows 客户端版本上执行的检查明确在 JVM 中进行,目的是为了不使迷你转储文件(可能相当大)填满 Windows 客户端用户的磁盘空间。然而,在 Windows 服务器上,迷你转储默认启用。
如何启用核心转储/迷你转储
JDK 9 及更高版本
要为任何操作系统在 JDK 9 及更高版本上启用核心转储,只需向 Java 启动器添加 -XX:+CreateCoredumpOnCrash 参数即可。
java -jar crasher.jar -XX:+CreateCoredumpOnCrash
如果您想禁用核心转储,则用减号替换加号:-XX:-CreateCoredumpOnCrash。
Windows 上的 JDK 8
在运行 JDK 8 的 Windows 客户端版本上,添加 -XX:+CreateMinidumpOnCrash 参数可在 JVM 崩溃时创建小型转储。
java -jar crasher.jar -XX:+CreateMinidumpOnCrash
如果您想禁用 Windows 服务器上的核心转储,则用减号替换加号:-XX:-CreateMinidumpOnCrash。
在运行 POSIX 操作系统的 JDK 8 中没有禁用核心转储的 JVM 参数。相反,您必须在操作系统级别禁用核心转储。
Unix、Linux 和 macOS 核心转储
在 POSIX 操作系统上,可以在操作系统级别禁用核心转储。在这种情况下,JVM 将报告“核心转储已被禁用”。
无法写入核心转储。核心转储已被禁用。要启用核心转储,请在再次启动 Java 之前尝试“ulimit -c unlimited”
要控制核心转储文件大小,请使用 ulimit 命令和 -c 参数。将其设置为 0 以禁用核心转储,设置为 unlimited 以启用核心转储。如果您运行 ulimit -c unlimited,则将为所有用户和所有程序启用核心转储。因此,首先在操作系统级别启用核心转储,然后运行 Java 程序。请记住,对于 JDK 9 及更高版本,您需要添加 -XX:+CreateCoredumpOnCrash。
ulimit -c unlimited
java -jar crasher.jar -XX:+CreateCoredumpOnCrash
参数摘要
如果在表格中进行总结,可以看出在 JDK 9 及更高版本中,核心转储/小型转储的处理更加一致。一致性通过 JDK-8074354,“将 CreateMinidumpOnCrash 设为新名称并在所有平台上可用” 添加到 JDK 9 中。以下两个表格分别总结了启用和禁用核心转储写入的参数和操作系统要求。请注意加号和减号。
启用核心转储
在此表格中,粗体条目标记了覆盖默认行为所需的设置(即,仅在 Windows 客户端上需要显式启用核心转储)。
| 操作系统 | JDK 8 参数 | JDK 9+ 参数 | 操作系统控制要求 |
|---|---|---|---|
| Windows 客户端 | -XX:+CreateMinidumpOnCrash |
-XX:+CreateCoredumpOnCrash |
不适用 |
| Windows 服务器 | -XX:+CreateMinidumpOnCrash |
-XX:+CreateCoredumpOnCrash |
不适用 |
| POSIX | N/A(始终启用) |
-XX:+CreateCoredumpOnCrash |
ulimit -c unlimited |
禁用核心转储
第二个表格显示了如何禁用核心转储。粗体条目显示了需要覆盖默认值的位置。
| 操作系统 | JDK 8 | JDK 9- | 操作系统控制要求 |
|---|---|---|---|
| Windows 客户端 | -XX:-CreateMinidumpOnCrash |
-XX:-CreateCoredumpOnCrash |
不适用 |
| Windows 服务器 | -XX:-CreateMinidumpOnCrash |
-XX:-CreateCoredumpOnCrash |
不适用 |
| POSIX | N/A(始终启用) |
-XX:-CreateCoredumpOnCrash |
ulimit -c 0 |
在核心转储中可以找到哪些 hs_err 文件中找不到的内容?
核心转储是对 hs_err 文本文件的极好补充。要检查它,您需要一个本机调试器。
我们只需查看生成的 hs_err 文件,就可以看到很多东西。
# Problematic frame:
# C [dump.dll+0x1006]
#
# Core dump will be written. Default location: D:\dumpster\hs_err_pid29804.mdmp
[...]
Native frames: (J=compiled Java code, j=interpreted, Vv=VM code, C=native code)
C [dump.dll+0x1006]
Java frames: (J=compiled Java code, j=interpreted, Vv=VM code)
j jaokim.dumpster.Divider.native_div_call(I)I+0
j jaokim.dumpster.Divider.do_div(I)I+2
j jaokim.dumpster.Dumpster.do_loops(I)V+16
j jaokim.dumpster.Dumpster.doTestcase(Ljava/lang/Integer;)V+5
j jaokim.dumpster.Dumpster.main([Ljava/lang/String;)V+58
v ~StubRoutines::call_stub
siginfo: EXCEPTION_INT_DIVIDE_BY_ZERO (0xc0000094)
我们可以看到,崩溃发生的 问题帧在 dump.dll 的本机代码中,并且写入了核心转储。本机方法是由 jaokim.dumpster.Divider.native_div_call Java 方法调用的。我们还可以看到似乎是某种除以零异常 (EXCEPTION_INT_DIVIDE_BY_ZERO)。然而,如果我们想从 dump.dll 中的本机代码获取更多详细信息,hs_err 文件除了这些内容之外,对我们没有任何帮助!
要获取这些缺失的详细信息,我们必须使用本机调试器(例如 Windows 上的 WinDbg)和生成的 core dump。下面是一个 WinDbg 屏幕截图,直接指向 崩溃行!
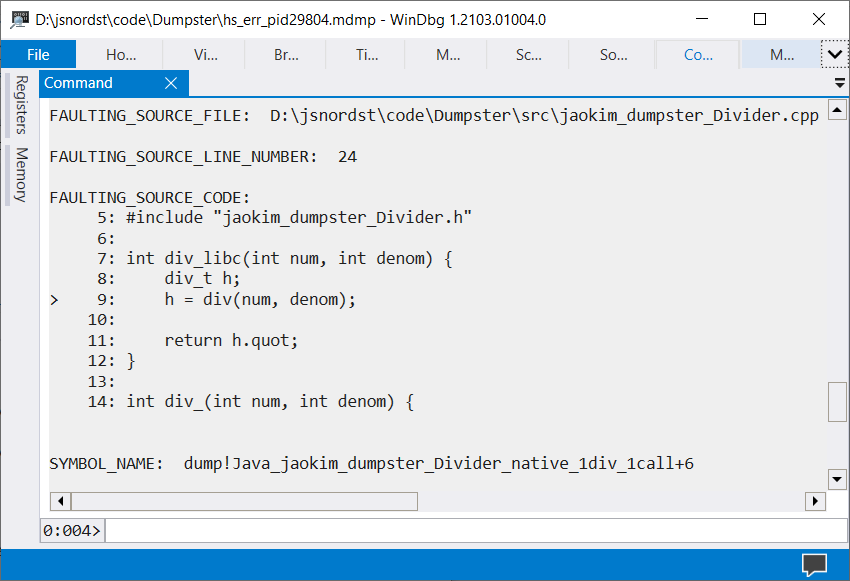
要找到确切的源代码行,本机调试器需要具有调试符号。对于 Windows,这些符号在编译 dump.dll 时生成的 .pdb 文件中。(你可以将 .pdb 文件放在与 coredump 相同的目录中,以便 WinDbg 找到它。)在 POSIX 操作系统上,共享对象 (dump.so) 需要在启用调试符号的情况下进行编译。
总结
当 JVM 崩溃时,它可以写入一个核心转储,其中包含已崩溃进程的详细信息。如果禁用了核心转储写入,JVM 将告诉你它无法写入核心转储——但这与 JVM 崩溃的实际原因无关。在大多数情况下,崩溃的原因可以在 hs_err 文件中找到,而更复杂的信息可以在核心转储中找到。
通常,大多数开发人员不需要核心转储,而应该专注于 hs_err 文件,以首先找到导致崩溃的组件。
用于崩溃的示例代码 可在我的 GitHub 上获得。