
扩展 C2 编译器的自动向量化功能
2021 年 1 月 27 日这里介绍的工作是作为 Oracle、乌普萨拉大学和 KTH 之间的联合研究项目的一部分进行的。关注 inside.java 上的博客系列,了解更多关于在斯德哥尔摩的 Oracle 开发办公室进行的 JVM 研究。
大家好!
我叫 William Sjöblom。在 2020 年下半年,我在 Oracle 撰写了我的硕士论文,结束了我在林雪平大学的五年制计算机工程硕士学位的最后一年。
在我的硕士论文中,我研究了 OpenJDK 中 HotSpot C2 编译器自动向量化的更多机会。具体来说,我研究了具有跨迭代依赖关系的最内层循环的自动向量化,最初的目标是处理 Java 类库中反复出现的多项式哈希函数。也就是说,让 C2 意识到这些哈希函数中的数据并行性,以生成高性能的 SIMD 代码。
为了实现这一点,添加了一个额外的循环优化过程。这个新的过程提取了循环体数据流的基于树的表示,其中节点代表基本操作(例如二元运算和数组加载)。然后根据一组重写规则对这棵树进行修剪,以便如果初始树对应于预定义的习语,则这棵树将被修剪为单个节点。在这种情况下,习语指的是编译器已知其更高效 SIMD 实现的已知计算内核。因此,如果修剪过程产生了一个节点,我们只需将正在优化的循环替换为我们预定义的 SIMD 实现。
在其当前状态下,优化过程了解两个独立的习语:归约和前缀和。归约习语包含各种数组归约(包括之前讨论的多项式哈希函数),并使用 递归加倍 技术来实现其 SIMD 实现。前缀和习语(实现是为了证明该技术的通用性)包含计算数组所有运行总和的循环,并使用 Hillis 和 Steele 提出的并行前缀和算法来实现其 SIMD 实现。
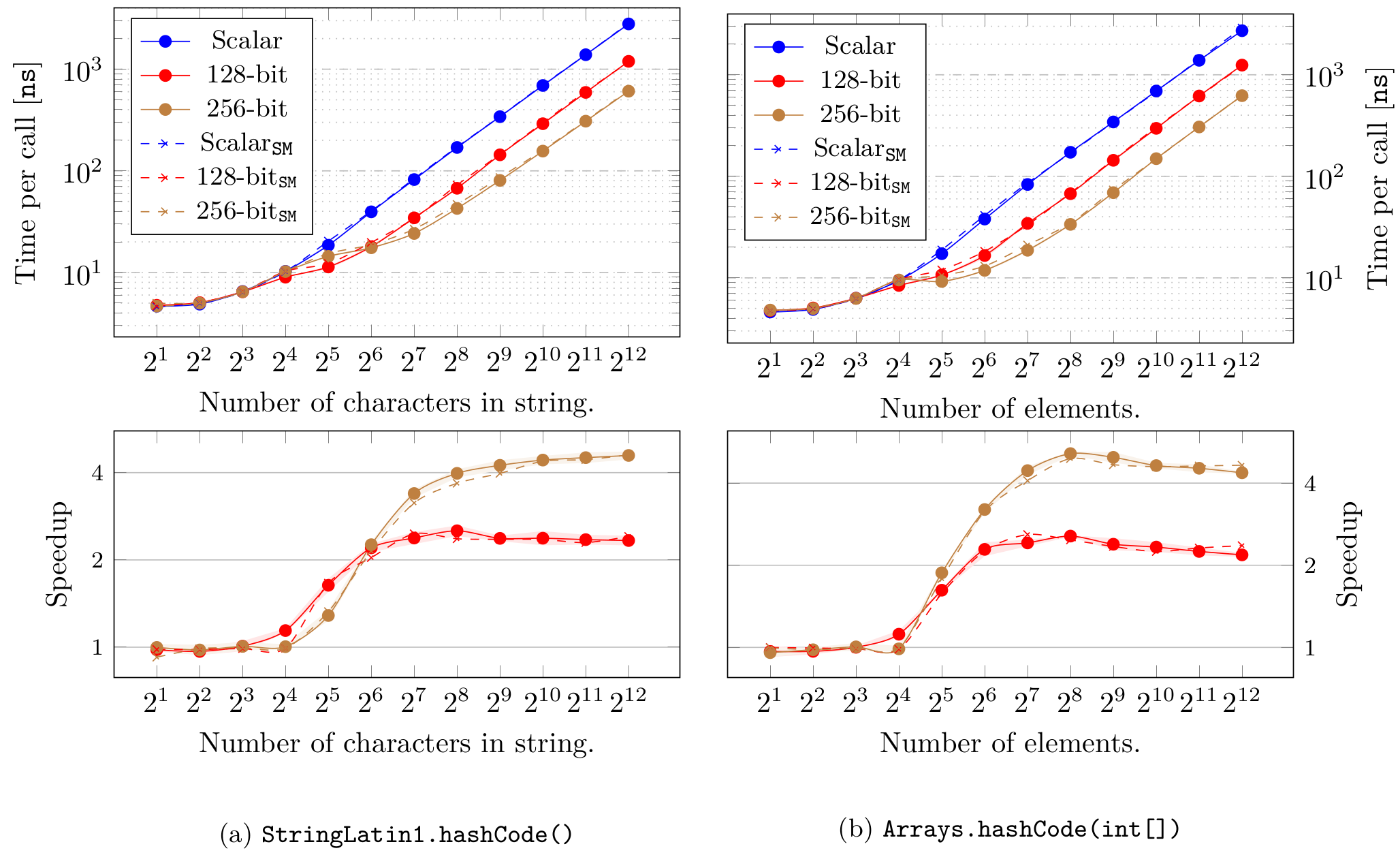
以上是性能评估中两个更有趣的结果,其中包含两个之前提到的多项式哈希函数的性能数据。这些图表显示了基线标量实现和我们自动向量化实现(使用 128 位和 256 位向量长度)的性能数据。如您所见,通过利用这些方法中提供给我们的数据并行性,可以获得性能提升。同样,我们观察到前缀和的加速效果非常显著,这表明对重复出现的计算内核进行向量化确实是一种值得的做法。
我现在已经完成了我的硕士论文和整个教育,我想感谢 Oracle 的 JPG 团队,他们给了我机会以如此高的姿态结束我的学生生涯,既让我有机会参与 HotSpot 这一伟大的工程,又给了我过程中所需的帮助。希望我的贡献有朝一日能合并到 OpenJDK 主线中,这样你也能体验到 String.hashCode 达到惊人速度的巨大喜悦。