
紧凑转发信息
2020 年 6 月 25 日此处展示的工作是作为 甲骨文、乌普萨拉大学和 KTH 之间的联合研究项目 的一部分进行的。关注 inside.java 上的博客系列,了解在斯德哥尔摩甲骨文开发办公室进行的 JVM 研究的更多信息。
这是我关于垃圾回收工作的简短描述,我为我的硕士论文做了这项工作。这项工作是与 甲骨文 合作完成的,这给了我一个机会与才华横溢的人才一起解决具有挑战性的问题。我想特别感谢我在甲骨文的导师,Per Lidén 和 Erik Österlund。
为了在垃圾回收环境中实现快速分配,一种常见的方法是使用指针碰撞分配。指针碰撞分配使用指向内存中第一个可用字节的指针,随着我们继续分配对象,该指针会单调增加。虽然此方案允许快速分配,但它有一个警告,即必须保持空闲内存连续。为了保持空闲内存连续,许多垃圾回收器在内存中移动对象以对其进行压缩,从而避免碎片,如下图所示。这通常在将所有活动对象移出页面然后释放该页面的过程中进行处理。这允许以 O(live) 对象清除页面,这通常是一个小数字(相对而言),因为大多数新创建的对象往往会很快死亡。
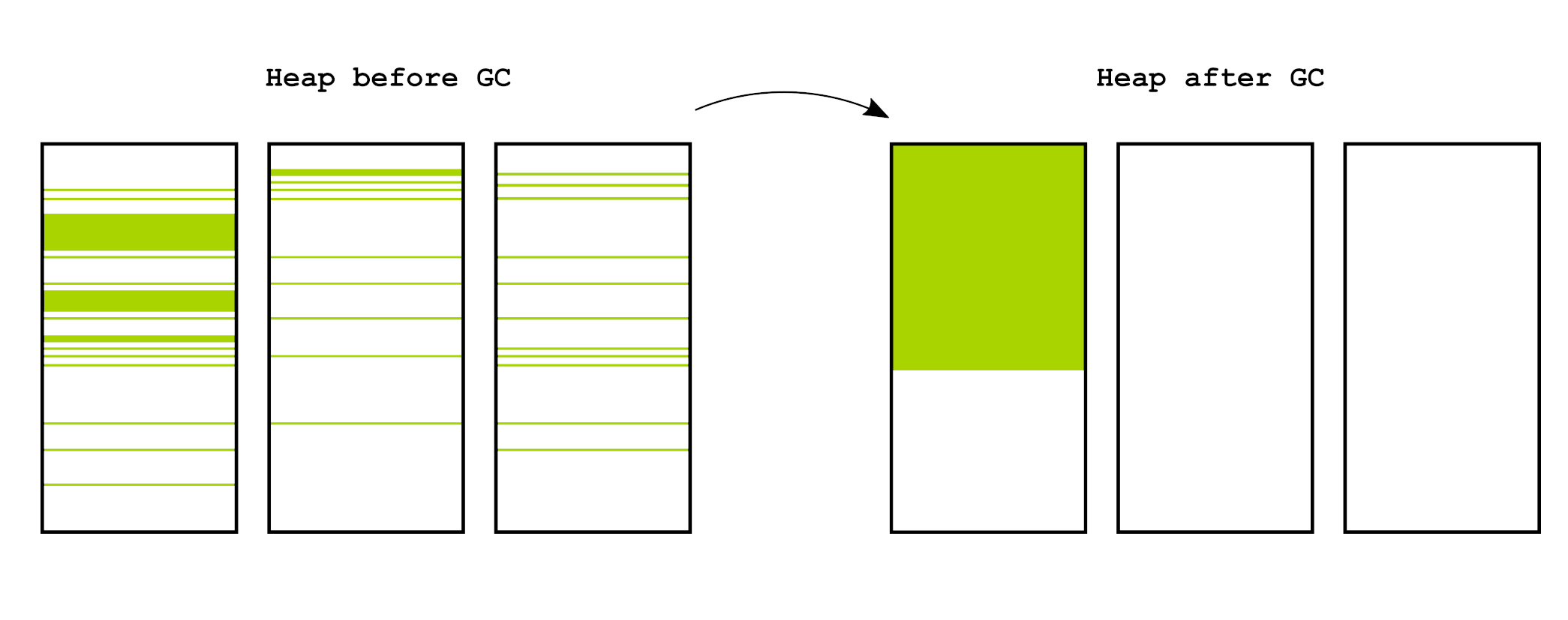
Z 垃圾回收器 (ZGC) 是 OpenJDK(可能运行你的 Java 应用程序的东西)中一个新的移动并发垃圾回收器 [1, 2]。ZGC 在不停止应用程序的情况下移动对象,以对抗内存碎片。这会以跟踪对象移动的形式给应用程序带来额外的开销,以便最终可以将所有指向它们的指针更新为新位置。通常在 GC 术语中,这称为转发信息。
ZGC 使用辅助转发表——针对快速查找进行了优化,但代价是增加了内存使用。该转发表存储在 Java 堆之外,称为堆外分配。任何堆外分配或在移动对象后保留旧对象都应视为内存开销,因为它严格需要 JVM,而不是实际的 Java 应用程序。ZGC 存在病态情况,在这种情况下,其转发信息的大小可能会变得非常大,从理论上讲,可能与堆本身一样大。如果我们针对病态情况调整应用程序的大小,这将浪费资源,因为内存使用通常会少得多。这可能使确定应用程序的内存需求变得困难。
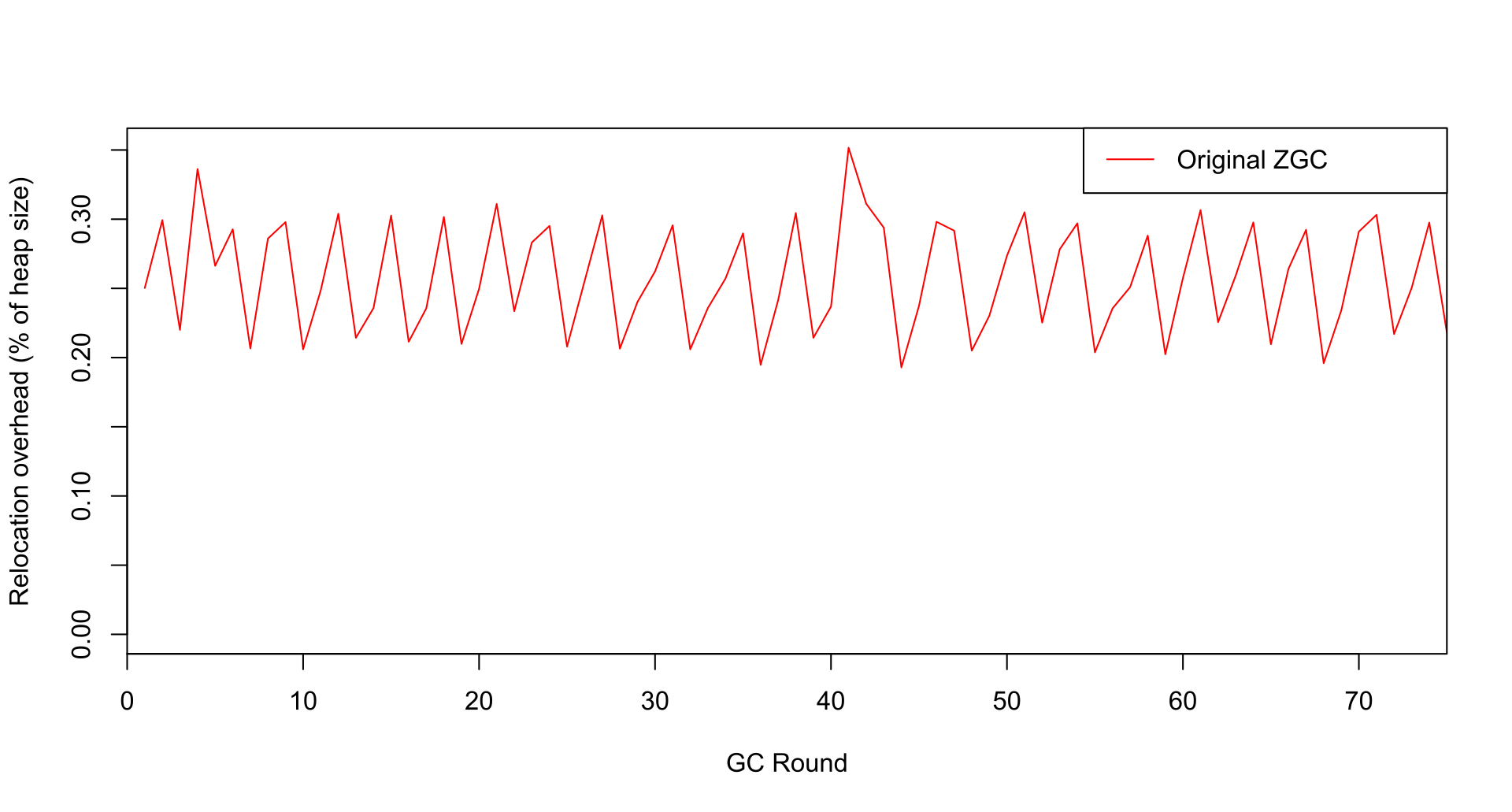
这种内存开销过大的风险不仅是理论上的担忧,而且可以在实际程序中观察到。下面是一个图表,描述了甲骨文内部基准应用程序 BigRamTester 的内存开销,显示了 35% 的内存开销。该应用程序的源代码可以在 此问题 中找到,作为附件。
存储每个从地址 A(源地址)到地址 B(目标地址)的已重定位对象的转发信息大约需要 128 字节(每个源/目标地址 64 字节),可以有效地以计算方式实现,但会增加额外的内存开销(如上所示)。作为我的论文工作的一部分,我们提出了一种新的转发表设计,它将几个稀疏填充的页面(即,活动对象较少)映射到一个新页面,以便使用源地址和活动信息计算目标地址。该设计生成一个压缩的转发表,其理论上最坏情况下的内存开销小于 3.2%。
在 ZGC 中,应用程序线程和垃圾收集器线程在重定位对象时可能会发生争用。争用会导致对象被重定位到的地址不确定。新设计需要确定性地址,以便我们可以根据一些信息集计算新地址。假设我们有一个旧页面 X,其对象将被重定位到新页面 Y。如果我们按照从头到尾遍历活动映射时遇到的顺序将对象复制到 Y 中,按升序排列,则可以获得确定性地址。
新设计将页面分成 Q 个块。一个块包含该块之前的所有活动对象。要获取之前活动对象的大小,您将使用关联的块并扫描未被该块覆盖的地址的活动映射。这允许有效地计算 X,并允许在所有对象都被重定位后立即释放旧页面,但会占用一些空间。下面描述了一个将页面分成块的示例。
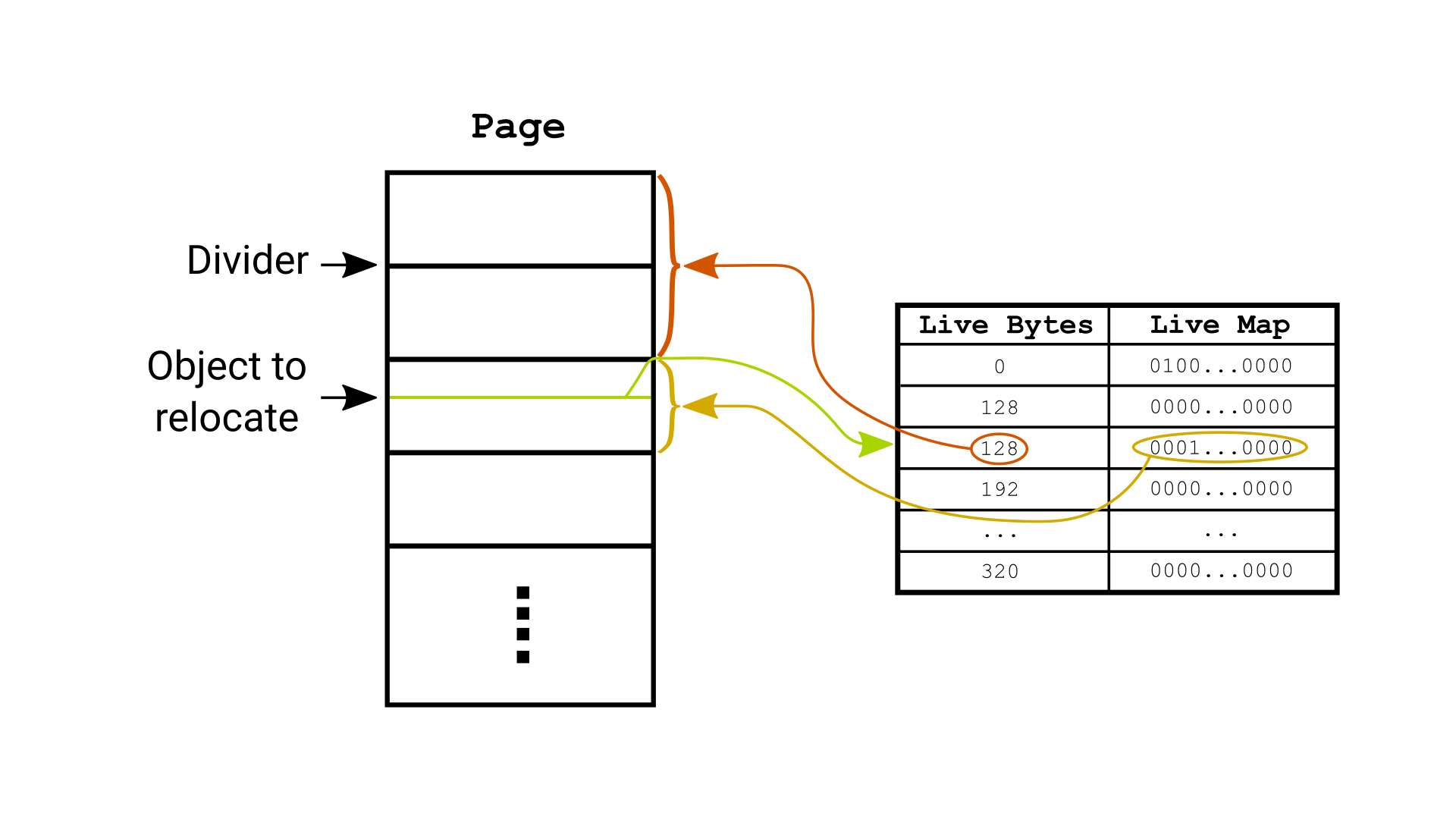
每个页面分隔符对应一个块的活动映射覆盖范围。在该示例中,要重定位的对象位于第三个块覆盖的第三个页面上(绿色箭头)。为了找到地址,我们不必扫描之前的块,因为活动字节字段描述了所有前一个块的活动字节数(红色箭头)。可以在块内的活动映射中找到在绿色对象之前的所有活动对象(及其大小)(黄色箭头)。
此设计导致一个简单的逻辑来计算新地址,其伪代码表示为
inline uintptr_t ZCompactForwarding::to_address(uintptr_t from_address) {
uintptr_t to_page_start_address = to_page_start_address(from_address);
uintptr_t live_bytes_before_chunks = live_bytes_before_chunks(from_address)
uintptr_t live_bytes_on_chunks = live_bytes_on_chunks(from_address);
return
to_page_start_address +
live_bytes_before_chunk +
live_bytes_on_chunks;
}
实施被证明具有小于 3.2% 的最大内存开销。我使用了 DaCapo 基准套件和 SPECjbb2015 基准来评估设计对执行时间的影响,因为现在必须计算转发地址,而不是查找转发地址。自然,我们预计会有一些性能下降。基准测试的结果显示,新设计的平均性能下降约为 2%,具有统计学意义。值得注意的是,DaCapo 中的许多程序根本没有受到影响。对于新设计,两个 DaCapo 程序的性能分别提高了 5.69% 和 22.42%。
我还没有实现我列表中的所有优化(尚未实现)。但我相当有信心,内存占用减少和可预测的开销超过了执行时间的增加,正如测量结果所示。这意味着您刚刚阅读过的工作有望进入 OpenJDK。只有时间才能证明一切。
参考文献
[1] Lidén P. CFV:新项目:ZGC;2017。
[2] Lidén P, Karlsson S. JEP 333:ZGC:可扩展的低延迟垃圾收集器。